현장 불확실성이 높은 인공지능(AI) 개인정보 영역의 첫 번째 규율체계(가드레일)로서 공개된 개인정보의 안전한 활용방안을 모색한다.
개인정보보호위원회(위원장 고학수, 이하 ‘개인정보위’)는 5월 3일 오후, 민간 전문가 및 관계부처 등이 참석한 가운데 AI 프라이버시 민·관 정책협의회 제2차 전체회의를 개최하고 ‘AI 개발·서비스를 위한 공개된 개인정보 활용 가이드라인(안)’에 대해 논의한다고 밝혔다.
챗GPT 등 대규모 언어모형(LLM) 개발의 핵심원료인 공개된 데이터에는 개인정보가 포함되어 있으나, 명확한 규율체계가 없어 회색지대가 발생하고 현장 불확실성이 높았다. 이는 AI 학습에 필수적인 공개된 데이터 활용의 제약요인으로 작용하였고, 공개된 데이터를 안전하게 활용하기 위한 기준 마련이 시급하다는 지적이 지속적으로 제기되어왔다.
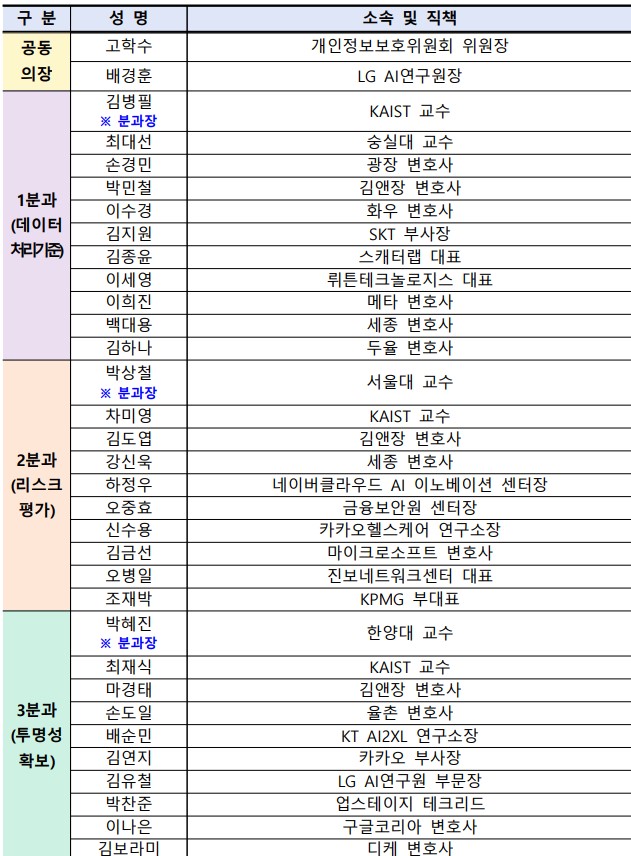
이에 개인정보위는 작년 11월부터 데이터 처리기준 분과를 중심으로 전통적 개인정보 처리와 구분되는 AI 학습·서비스의 특성, 공개된 개인정보 처리에 수반되는 프라이버시 위험 등을 종합적으로 고려하여 국내 개인정보 보호법제를 보완하는 가이드라인 마련 작업을 진행해왔다.
이번 정책협의회에서는 공개된 개인정보의 안전한 활용 관련 주요 법적·기술적 쟁점사항을 비롯하여 AI 개발·서비스 단계별로 공개된 개인정보를 적법하고 안전하게 처리하기 위한 기준 등을 담은 「AI 개발·서비스를 위한 공개된 개인정보 활용 가이드라인(안)」의 주요 내용을 공유하기 위해 마련되었다. 이후 진행될 전체토론에서는 학계, 산업계, 시민단체 등 각계 위원과 관계부처의 의견을 청취하고, 공개된 개인정보 규율체계의 합리성과 완성도를 높일 수 있는 방안을 함께 논의할 예정이다.
개인정보위는 이날 민간 전문가 및 관계부처가 제시한 의견을 검토·반영하고 개인정보보호위원회 전체회의 등을 거쳐 5월 중 가이드라인을 확정·발표할 방침이다.
김병필 카이스트 교수(데이터 처리기준 분과장)는 “국제적으로는 대규모 AI 모형을 학습하기 위한 데이터가 조만간 고갈될 수 있다는 우려까지도 제기되고 있으나 우리는 기존에 축적된 데이터도 충분히 활용하지 못하는 실정”이라며 “온라인상 공개된 정보를 AI 학습에 안전하게 활용할 수 있는 적절한 가이드라인을 통해 현장의 불확실성을 낮출 필요가 있다”라고 밝혔다.
공동의장인 배경훈 엘지(LG) 인공지능(AI)연구원장은 “생성형 AI의 발전은 점점 더 많은 학습데이터를 필요로 하고 있으며, 안전한 공개 데이터 활용은 더욱더 중요해지고 있다”라면서 “이에 AI 프라이버시 민·관 정책협의회에서 마련한 가이드라인은 시의적절하게 그 방향성을 제시하고 있으며, 앞으로도 다양한 이해관계자들과 협의를 통해 개인정보 보호와 AI 기술발전이 상호 보완적으로 이루어지는 건강한 생태계를 조성해나갈 수 있기를 기대한다”라고 밝혔다.
고학수 개인정보위 위원장은 “미국, 영국, 프랑스 등 주요국도 웹 스크래핑 방식으로 수집한 공개된 개인정보를 안전하게 활용하기 위한 사회적 논의를 본격화하고 있으며, 이러한 국제적 흐름에 발맞추어 혁신을 저해하지 않으면서 국민이 신뢰할 수 있는 기준이 마련될 수 있도록 지속적으로 의견을 수렴해 나가겠다”라고 밝혔다.
★정보보안 대표 미디어 데일리시큐 / Dailysecu, Korea's leading security media!★
